



MySQL数据库工程师入门实战课程视频教程
 5268 人在学
5268 人在学
分布式锁通常有很多选择,基于 Redis 的,基于 Zookeeper 的,基于数据库等等方案。
Redis 用于缓存数据,在项目中都有使用,所以使用 Redis 来做分布式锁的会稍微多些。
如果用 Redis 来做锁,可以直接用开源的方案,比如redisson。
最常见的使用方式如下所示:
获取锁对象,调用 lock()加锁,执行业务逻辑,调用 unlock()释放锁。
尽管框架提供的使用方式已经很简洁了,但是我们还是有必要对锁做一层包装。做包装的目的是为了提高扩展性和易用性。
抽象接口
如果说我们直接使用 redisson 的原生 API 做加锁,那么很多地方都会出现 RLock 相关的代码,突然有一天,由于某些原因,需要将锁进行替换,这个时候改动的范围就比较大了。每个使用了 RLock 的地方都得改。
如下图:很多 Service 都用到了 RLock.lock()方法,当我们需要替换锁的时候,所有涉及到的类和方法都得修改,改动的点如红色部分所示。
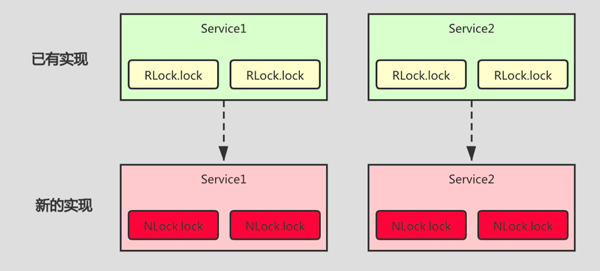
所以我们需要做一层抽象,可以定义一个 DistributedLock 接口来提供锁相关的能力,提供多种实现,这样方便替换和扩展。
如下图:每个 Service 中都是用的 DistributedLock 接口来加锁,当我们需要替换锁的实现时,使用的地方不需要改动,只需要替换 DistributedLock 的实现即可。
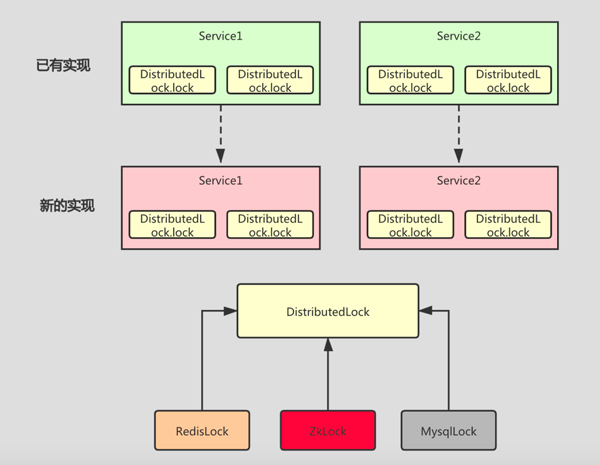
自动释放
自动释放指的是对于加锁之后,业务逻辑执行完毕需要自动关闭锁。按照前面 Redisson 的方式我们需要手动调用 unlock()来释放持有的锁。
当然 Redisson 也提供了超时释放的功能,正常情况下肯定是业务执行完毕就要释放锁了,同一个锁的下个请求才能继续接着处理。
手动释放资源最容易出现的问题就是忘记释放,所以在 JDk7 中引入了 try-with-resources 来自动释放资源,相信大家都很熟悉。
所以我们在封装的时候,尽量不要让使用者去手动释放,减少出错的概率。对于有结果的我们可以使用 Supplier 来传递你的逻辑,对于没有返回结果的可以用 Runnable 来传递你的逻辑。
使用:
容灾处理
另一个需要注意的问题就是锁的可用性,万一对应的 Redis 出问题了,这个时候去加锁肯定会失败,如果不做任何处理,就会影响正常的业务操作,导致业务不可用。
我们除了实现 Redis 的锁之外,还可以实现其他的锁,比如数据库锁。当 Redis 锁不可用的时候降级为数据库锁,虽然性能有所影响,但是不会影响业务。
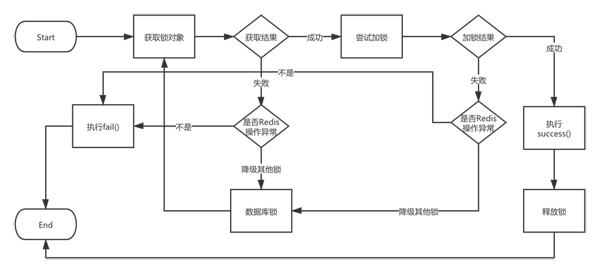
加锁流程
如果数据库锁也不可用了(题外话:所有都不可用可能性非常小),那还是让业务操作失败比较好。因为我们用加锁的场景,肯定是为了防止并发场景带来的问题,如果当锁不可用时,你将异常消费了,让业务操作继续下去,就有可能出现没有加锁的业务问题。
当然监控也非常需要,Redis, 数据库等监控。在出故障的时候,及时有人员介入。
监控体系
Redis, 数据库,Zookeeper 这些承载分布式实现的中间件的监控肯定是必须要有的。另一个监控就是更细粒度的对应锁这个动作的监控。
比如加锁的时间,释放锁的时间,在锁里面执行业务的时间,锁的并发量,执行次数,加锁失败的次数。
这些数据指标都非常重要,能够帮助你及时发现问题。比如 10 秒内几百次加锁失败,都降级成了数据库锁,这个时候你收到了警报,一看就知道 Redis 出问题了,及时解决。
监控方式就随便了,每个公司都不一样,你可以暴露数据给 Prometheus 抓取,也可以集成 Cat 做好埋点,只要能监控,能告警就可以了。
数据库中的数据是为众多用户所 共享其信息而建立的,已经摆脱了具体 程序的限制和制约。不同的用户可以按各自的用法使用数据库中的数据;多个用户可以同时共享数据库中的数据资源,即不同的用户可以同时存取数据库中的同一个数据。数据共享性不仅满足了各用户对信息内容的要求,同时也满足了各用户之间信息通信的要求。





